Transformer
Attention is all you need
공부 정리에 앞서 서울대 데이터사이언스학과 이준석 교수님의 강의 자료를 이용했다는 점을 명시합니다!
이전까지는 input data X를 가지고 output data Y를 표현하는 방식은 대표적으로 MLP, CNN, RNN등이 있었다. 각각 다른 모델이지만 결국에는 input data X에 대한 Weighted Sum으로 표현된다는 방식은 동일했다. 과연 Weighted Sum으로 표현하는 방법이 가장 좋은 output을 도출하는 방법일까? 라는 질문에서 시작된 모델이 바로 Transformer이다.
Basic Assumption: the input x can be split into multiple elements that are organically related to each other.
ex) $\circ$ People in Society
$\circ$ Words in Sentence
$\circ$ Frames in Video
그동안 우리는 예를 들어 “뛴다”라는 표현을 하나의 vector로 embedding하는 과정을 거쳤다. 하지만 사람이 어느 소속에 있느냐에 따라 역할과 행동이 다르듯이, “뛴다”라는 표현도 맥락에 따라 다르게 표현된다. 예를 들어 “운동장을 열심히 뛴다”와 “몸값이 말도 안되게 뛴다”에서 “뛴다”의 표현은 다르다. 그래서 한 사회 안에서 사람간의 관계가 있고, 문장안에 단어간의 관계가 있듯이, 각각의 Element들은 속해있는 Context안의 다른 Element들과의 관계를 고려해서 own representation을 정의한다. 이를 self-attention 기법이라고 정의한다.
Self-Attention
Each element learns to refine its own representation by attending its context (other elements in the input).
$\circ$ More Specifically, as a weighted sum of other elements (not arbitrary weights) in the sentence.
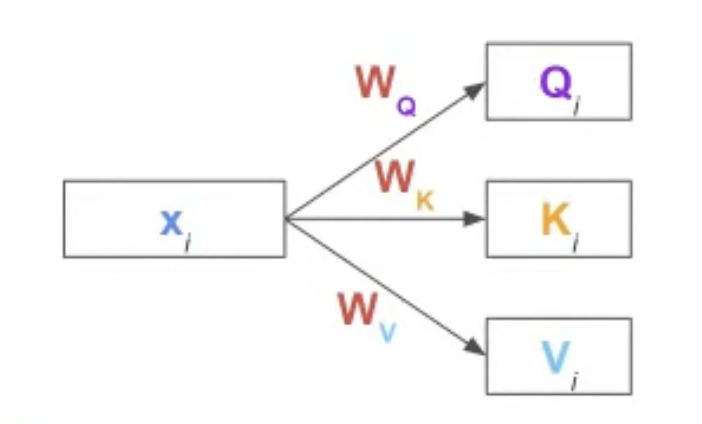
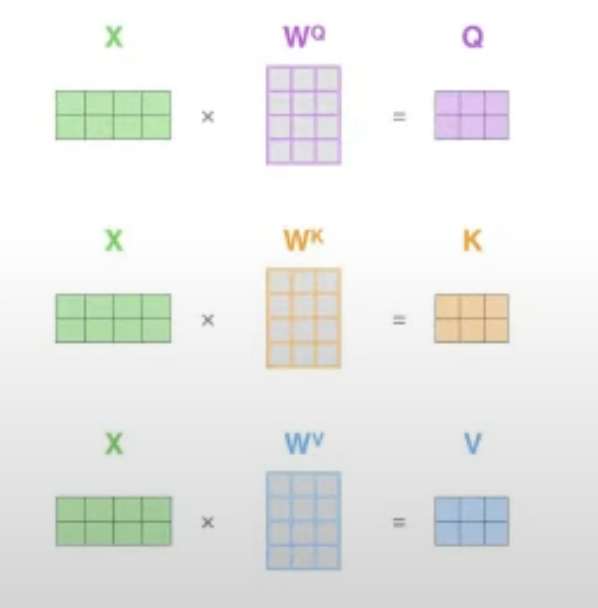
Input token {$x_1, x_2, \dots, x_N$}이 존재할 때, 각각의 Input token $x_i$에 대해서 linear transformation을 통해 우리는 Query, Key, Value값들을 직접 mapping한다.
Weight Paramerter $W_Q, W_K, W_V$는 모든 input에 shared 되는 parameter로 학습이 되는 learned parameter이다. 어떤 단어 vector가 주어졌을 때, Weight Parameter가 Query로써 역할을 할 때, Key로써 역할을 할 때, Value로서 역할을 할 때 어떤식으로 변환이 되어야하는 지에 대한 규칙을 학습을 한다.
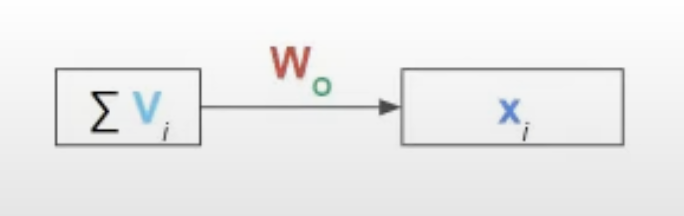
한 context 내의 vector들에 대한 Value값들의 Sum이 바로 특정 input token $X_i$에 대한 새로운 representation이 된다. 원래 input token과 같은 dimension으로 맞춰주기 위해 Value값들의 Sum은 $W_o$를 통해 새로운 vector로 최종적으로 변환이 된다. 그렇다면 Query, Key, Value값이 매핑되는 과정과 무엇으로 정해지는 지 알아보자.
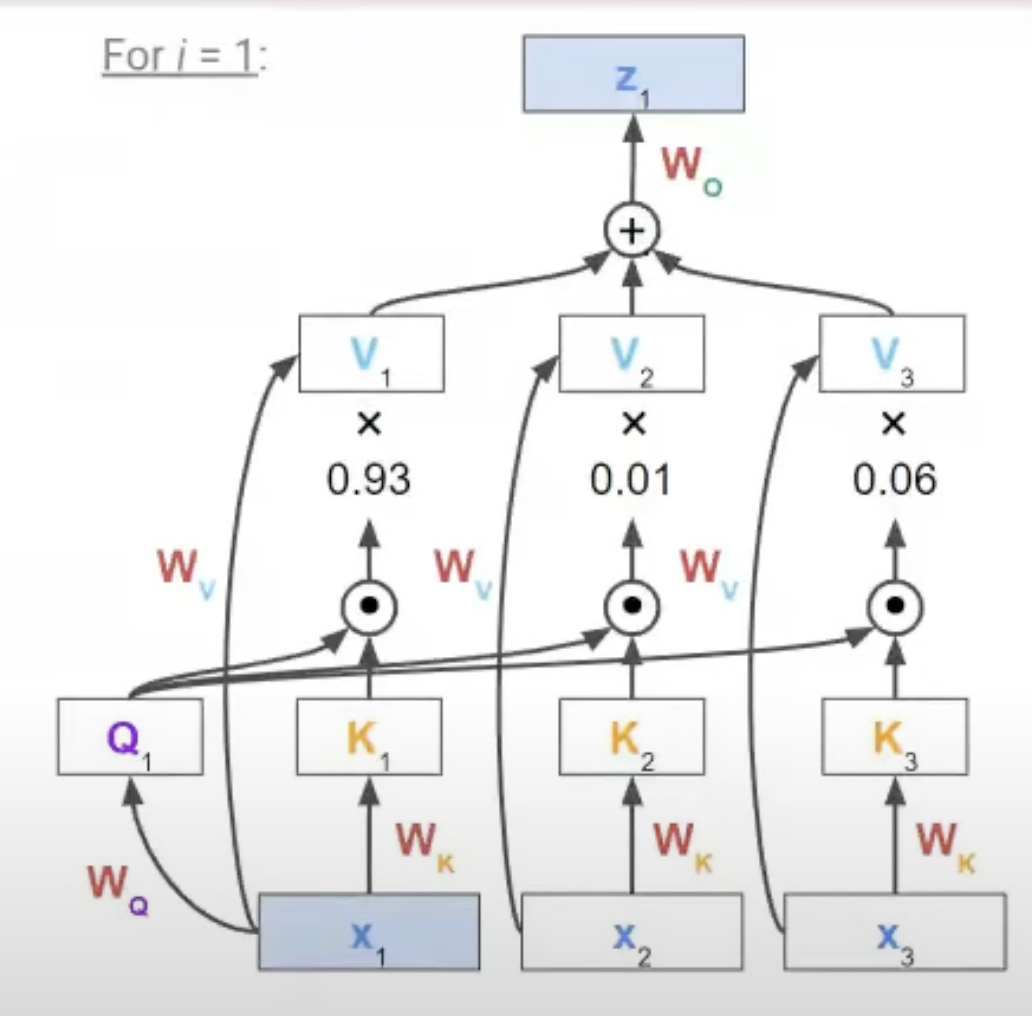
Input token $\in$ [$X_1, X_2, \dots, X_T$]에서 임의의 Input Token $X_i$는 $W_Q$와 곱해져서 Query가 된다.
모든 Input Token은 $W_k$와 곱해져서 각각 Key가 된다.
모든 Input Token은 $W_v$와 곱해져서 각각 Value가 된다.
Query가 된 $X_i$는 주체가 되어 자신을 포함한 모든 Input token들을 참조하여 attention score를 만들게 된다. 이 때, attention score는 Query와 Key의 dot product를 거치고 나온 모든 값들에 Softmax를 취해서 구한다.
구한 attention score와 Value값들을 각각 곱하고 나온 값을 다 더해서 값을 도출한다. 이 후, 원래 Input token $X_i$와 같은 크기로 맞춰주기 위해 $W_o$를 구해서 $X_1$을 새롭게 해석한 $Z_1$을 구한다. 이것을 새롭게 transform했다고 표현하고 이러한 모델을 transformer라고 한다.
위의 예시는 Query를 i=1일때의 input token으로 가정한 경우이며, 모든 input token 하나하나가 다 Query가 되도록 위의 과정을 거쳐주면 된다. i=1일때를 기준으로 식을 작성하면 다음과 같다.
Main: $X_0$
Query $Q_1$ = $W_Q \times X_1$
Key K = [$K_1, K_2, \dots, K_T$] = [$W_K \times X_1, W_K \times X_2, \dots, W_K \times X_T$]
Value V = [$V_1, V_2, \dots, V_T$] = [$W_V \times X_1, W_V \times X_2, \dots, W_V \times X_T$]
Attention score $\alpha$ = [$\alpha_1, \alpha_2, \dots, \alpha_T$] = [$Q_1 \times K_1, Q_1 \times K_2, \dots, Q_1 \times K_T$]
Outputs = $\sum_{i=1}^{T} (\alpha_i \times V_i)$
$Z_1$(Transformed $X_1$) = $W_o \times Outputs$
위의 i=1인 경우를 보면 알겠지만, 본인 자신과의 score가 당연히 가장 크게 계산이 되고 다른 token들과의 score도 reference정도에 따라 계산되는 것을 볼 수 있다. X -> Z로 가는 이 과정을 모든 vector에 대해 반복하는 모델을 우리는 transformer라고 하며 이 과정을 contextualize라고도 한다. 자신이 속해있는 그룹의 다른 모든 것들과의 의미 혹은 관계를 가져와서 그것들을 담은 vector로 transform한다는 것이다.
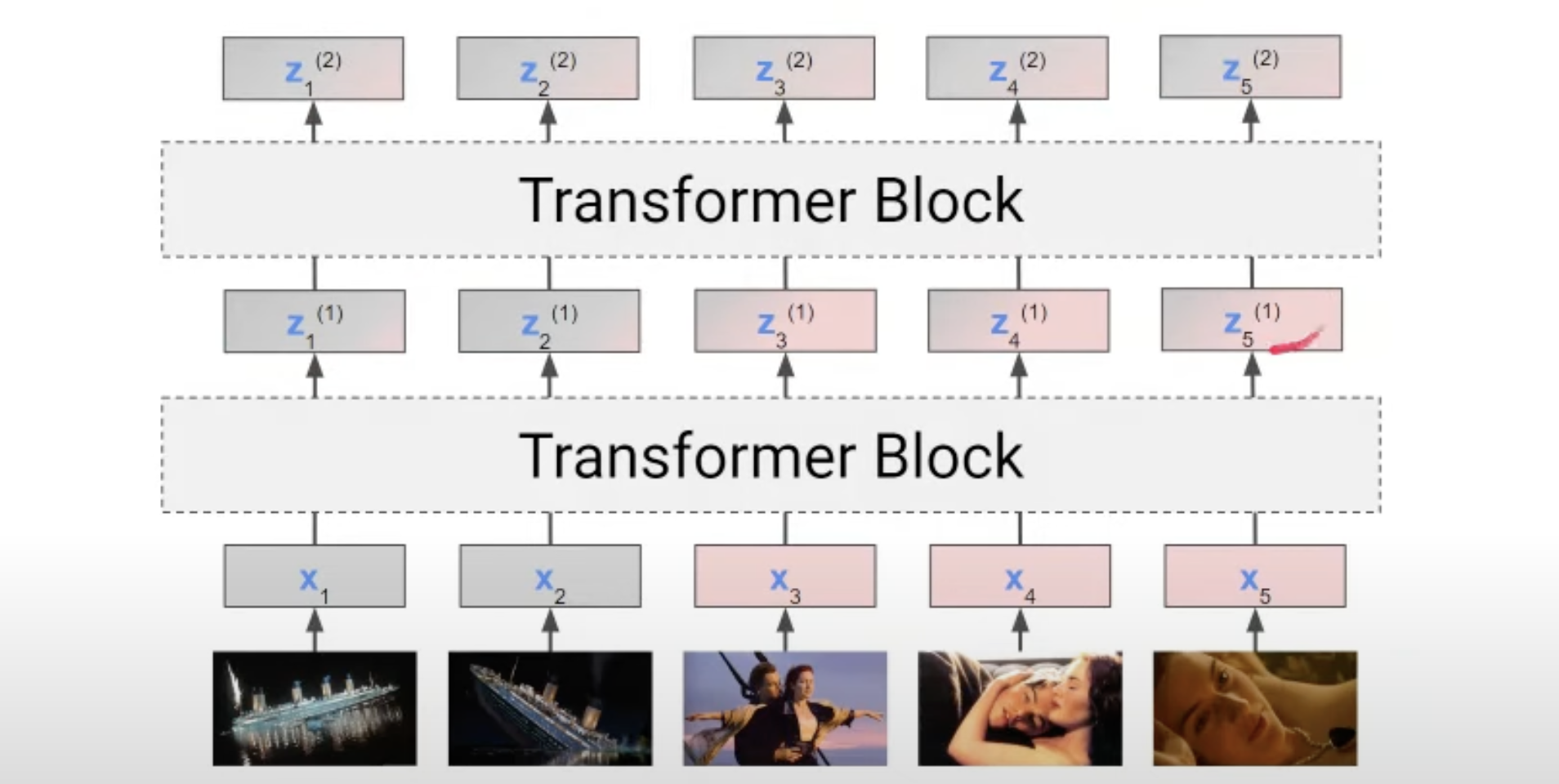
모든 input vector or token에 대해 위의 과정을 거치면 input vector 개수 만큼의 Z가 나올 것이고 이를 거치는 모델을 하나의 Transformer Block이라고 볼 수 있다. 실제 모델에서는 이러한 Transformer Block을 여러번 거쳐서 최종 Z를 구한다. 아래 그림을 보면 지금까지 Transformer 설명에 대한 큰 요약이라고 볼 수 있다.
만약 Transformer를 통해 input text등을 가지고 긍정/부정 분류, 감정분류, 값 예측 등을 진행하고 싶다면 우리는 transformer를 통해 나온 Z값들을 아우르는 하나의 값을 필요로 할 것이다. 이 때 나온 Z값들을 average한 값을 가지고 원하고자 하는 Classifiy, Regression 문제를 위해 Classifier, Regressor에 넣어서 값을 도출할 수도 있겠지만, 이 방법은 문제가 있다. 특정 i에 대한 $Z_i$값은 Transformer Block을 통해 모든 input token들을 고려한 attention기법을 사용했더라도 $X_i$의 특징이 가장 많이 반영되어 있기에 단순히 나온 모든 Z값들을 평균낸다면 그냥 입력 token들의 Average를 구하는것과 크게 다를바 없을 것이다. 즉, attention 효과를 거의 못본다는 것이다. 그래서 Transformer Block내에서 입력 token들의 특성을 균형적으로 반영할 수 있도록 dummy token(Classification Token; CLS)을 넣어주면 모든 input token을 균형적으로 attention한 Z값을 얻을 수 있게 된다. dummy token이 Transformer를 거쳐서 나온 Z값으로 우리는 원하는 Classify or Regression을 진행할 수 있다. 이 과정을 그림으로 나타내면 아래와 같다.
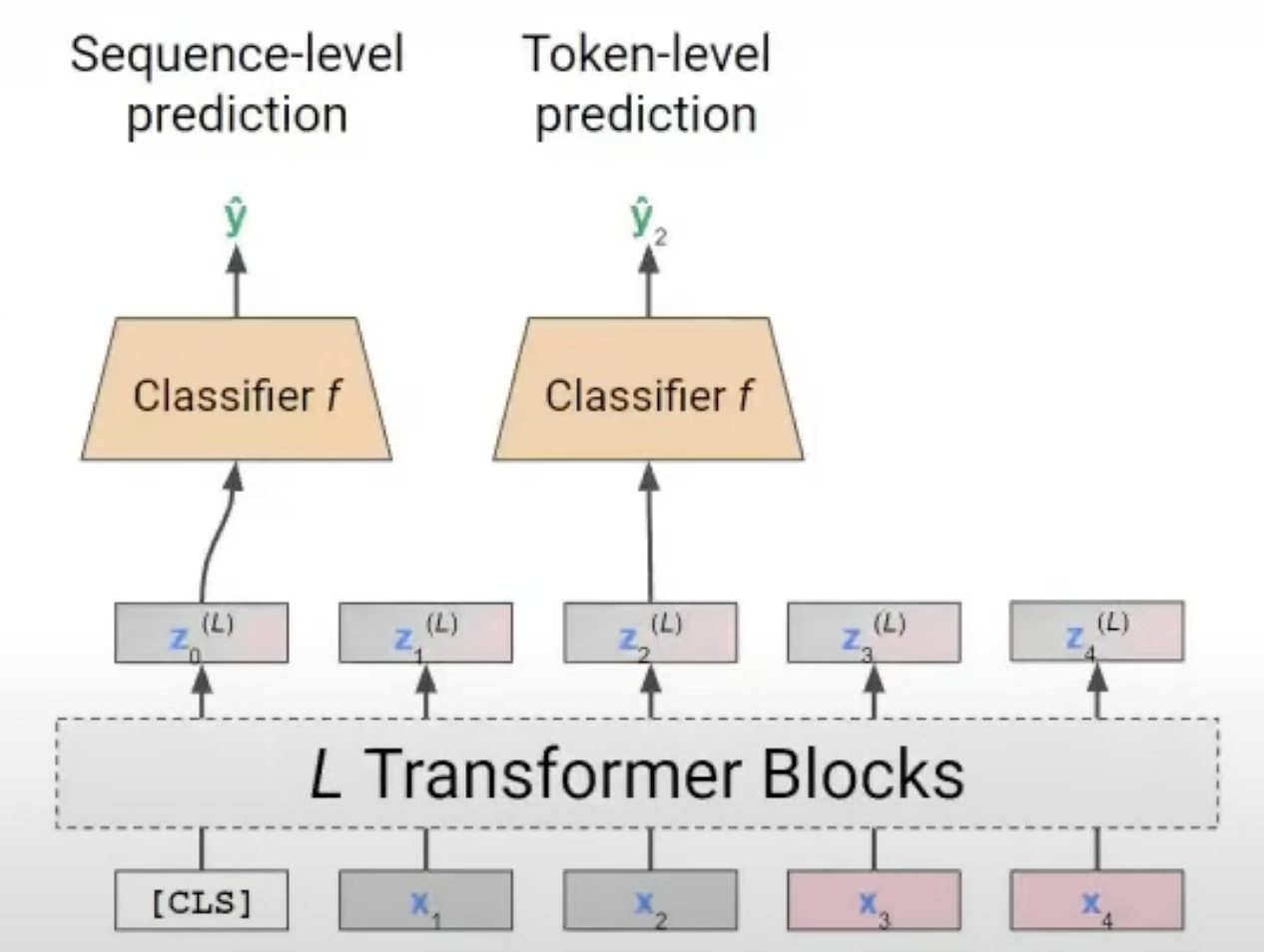
여기 까지가 Transformer의 주된 내용이지만 아직 다루지 않은 부분들이 있다.
- Transformer를 이용해 궁극적으로 우리는 무슨 문제를 풀 것인가?
- Transformer Model을 어떻게 학습시킬 것인가?
- RNN과 달리 token의 어순에 대해서는 고려하지 않았는데, 어순까지 고려하려면 어떻게 설계해야 하는가?
More details on Transformers
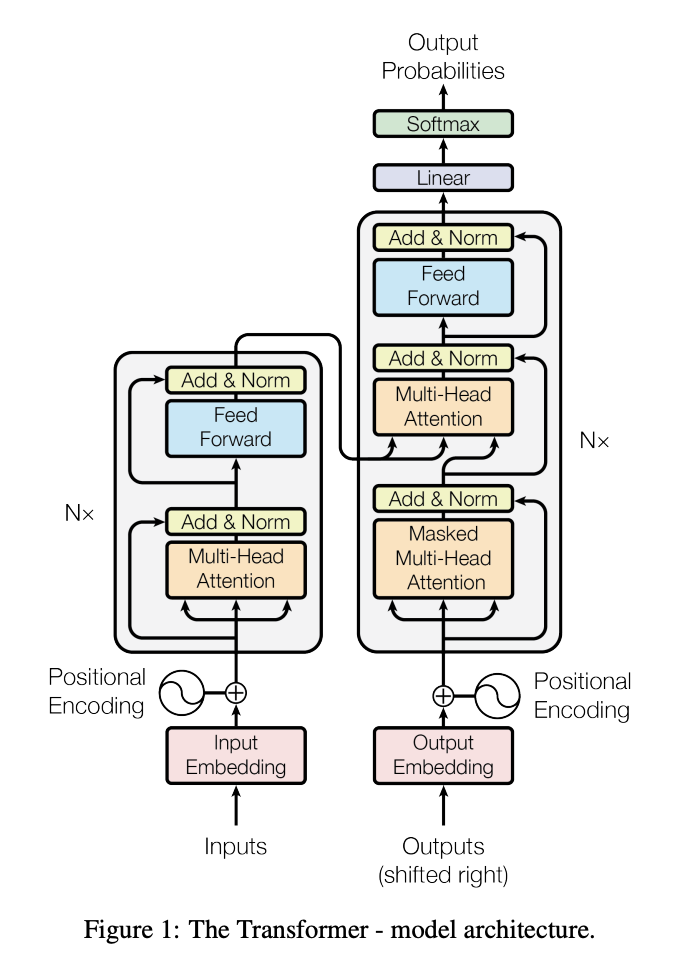
Encoder
Embedding된 Input token들을 이용해서 Encoder에서는 정보를 압축하는 과정을 거친다.
Multi-Head Attention을 통해 Input token들간의 관계에 많이 집중을 한다.
그리고 Feed Forward에서는 Attention을 거친 output이 token간의 관계가 아닌 나 자신을 더 잘 표현할 수 있도록 하기 위해 additional FC Layer를 거쳐 나온다. 이러한 과정을 한 두번 거쳐서는 사실 input token들이 자신들을 가장 많이 참조하여 attention되기에 다른 token들과의 관계까지 잘 고려되어 변하기는 힘들다. 따라서 N번 반복하여 token들 간의 관계를 잘 반영하여 Encoding되도록 하는 것이다. N번 거치려면 Output과 Input의 차원이 같아야 계속 이어지며 진행될 수 있기 때문에 Transformer에서는 Output은 Input Embedding이 된 token들과 크기가 무조건 같아야 한다.
중간에 존재하는 Add&Norm은 Residual Connection과 Layer Normalization을 의미하는데, 이는 Multi-head Attention을 이용하지 않거나 Feed Forward를 이용하지 않을 때 사용할 수 있도록 만들어 놓은 것이다.
Step1. Input Embedding
Inputs는 Sequence로 이루어진 token 혹은 Image, Video등이 될 수 있다. 이 때, 이들을 model에 넣어서 연산을 하기 위해서는 Vector 형태로 변환이 되어야 한다. 따라서 Input Embedding을 통해 Inputs data를 Vector화 시켜줘야 한다. output은 vector들의 sequence한 형태로 나온다. 대표적인 방법으로는 Word2Vec, TfidfVectorizer등이 존재한다.
Step2. Positional Encoding
기존 RNN, LSTM은 input vector 하나당 hidden state와의 상호작용을 통해 output을 내고 그 다음 input vector가 들어가는 방식으로 input vector의 sequence가 자동으로 고려되는 특징을 보였다. 하지만 그러기에 속도는 매우 느렸다. Transformer는 input vector를 token마다 하나씩 처리하는 방식이 아닌 전부 다 Model에 넣어서 병렬적으로 처리하기에 속도는 매우 향상되었지만, Sequence의 순서를 반영하지 못한다는 점이 문제점이었다.
- Although I’m not a smart, I can do it.
- Although I’m smart, I can not do it.
위의 문장 1,2는 not의 위치만 다르지만 문장의 의미는 아예 다르다는 점을 알 수 있다. 따라서, Transformer는 sequence의 순서도 역시 고려해야만 한다. 그러기 위해서는 지켜야 할 규칙이 있다.
- 단어 의미가 변질되지 않도록 더해줘야 할 위치 벡터값이 너무 크면 안된다.
- 같은 위치의 토큰은 항상 같은 위치 벡터값을 가져야 한다.
이러한 규칙을 지키며 Input Embedding이 된 vector에 token들의 위치 정보를 고려한 위치정보 Embedding값을 더해줘야 순서를 고려할 수 있다. 위의 규칙을 모두 지키면서 위치 벡터를 더해주는 방법을 사용하기 위해 본 논문에서는 sine & cosine 함수를 사용하였다.
Sine & cosine 함수는 우선 -1에서 1사이로 값이 고정되기에 위치 벡터값을 한정시킬 수 있다.
또한, 주기함수 이기에 sequence의 길이가 아무리 길어도 적절히 잘 매핑 시킬 수 있다.
다만, 주기함수 이기에 서로 다른 위치의 token들이 같은 위치 벡터값을 가지는 경우가 발생하는데, 이를 방지하기 위해 위치 벡터의 홀수번째 차원에는 cos값을 매핑한 값을 부여하고 짝수번째 차원에는 sin값을 매핑한 값을 부여한다. 이렇게 되면 주기가 딱 맞물려서 sin값이 같더라도 cos값은 다르기에 결국 다른 위치벡터값이 매핑되는 것을 알 수 있다.
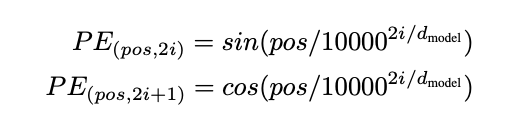
Step3. Contextualizing the Embeddings
왼쪽에 있는 네모 박스가 Encoder인데, Nx 로 이루어져있는 것으로 보아 여러 개의 박스로 이루어져 있다고 볼 수 있다. 박스 안의 구조는 크게 두가지인데 Multi-Head Attention과 Feed Forward이다. Multi-Head Attention을 보면 세 가지 input이 들어가는 것을 볼 수 있는데, 이것이 바로 Q, K, V이다. 위의 i=1인 경우의 self-attention의 과정을 나타낸 그림을 수식으로 나타내면 아래 식과 동일하다.
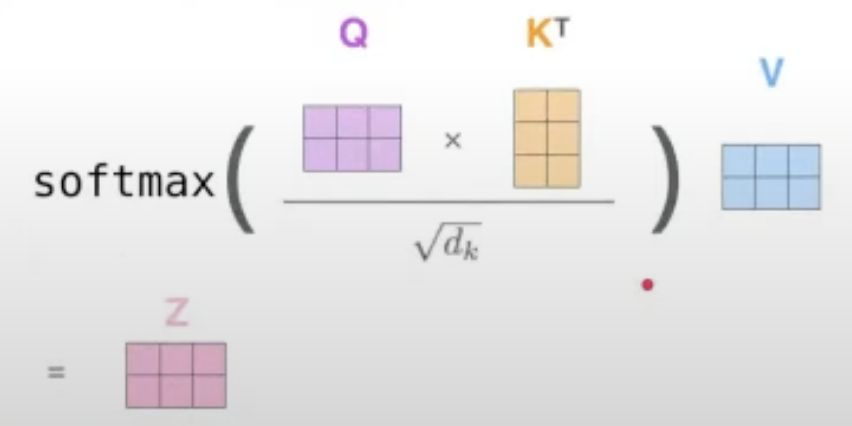
-
Query, Key, Value representations
For each word, we learn to map it to Q,K,V; instead of using the original embedding, (usually smaller) representation to work like a query, key, value by linear transformation.
-
Self-Attention
For each input word as Query(Q), we compute similarity with all words as key(K), including the queried word, in the sentence.
Then, all the words as value(V) are weighted-summed.
-> This is the attention value(Z), the contextualized new word embedding of same size. -
Multi-head Self-Attention
-
The animal didn’t cross the street because it was too tired.
-
The animal didn’t cross the street because it was too narrow.
1,2번 문장에서 문맥상으로 it은 서로 가리키는 대상이 다르다. 따라서 Head를 하나가 아닌 여러 개를 둬서 문장 타입에 집중하는 attention, 명사에 집중하는 attention, 관계에 집중하는 attention등 여러 가지의 Z값을 만들어서 표현한다면 문장 간의 복잡한 관계를 더 잘 이해하고 많은 정보를 표현할 수 있기에 multi-head attention기법을 사용한다.
n개의 Head를 사용한다고 하면 최종 output에는 $Z_0, Z_1, \dots, Z_{n-1}$이 나오고 이들을 concat한 후 원래 input token size와 같도록 새로운 $W_o$를 지정해서 곱해주면 모든 의미를 담은 새로운 Z가 탄생한다.
-
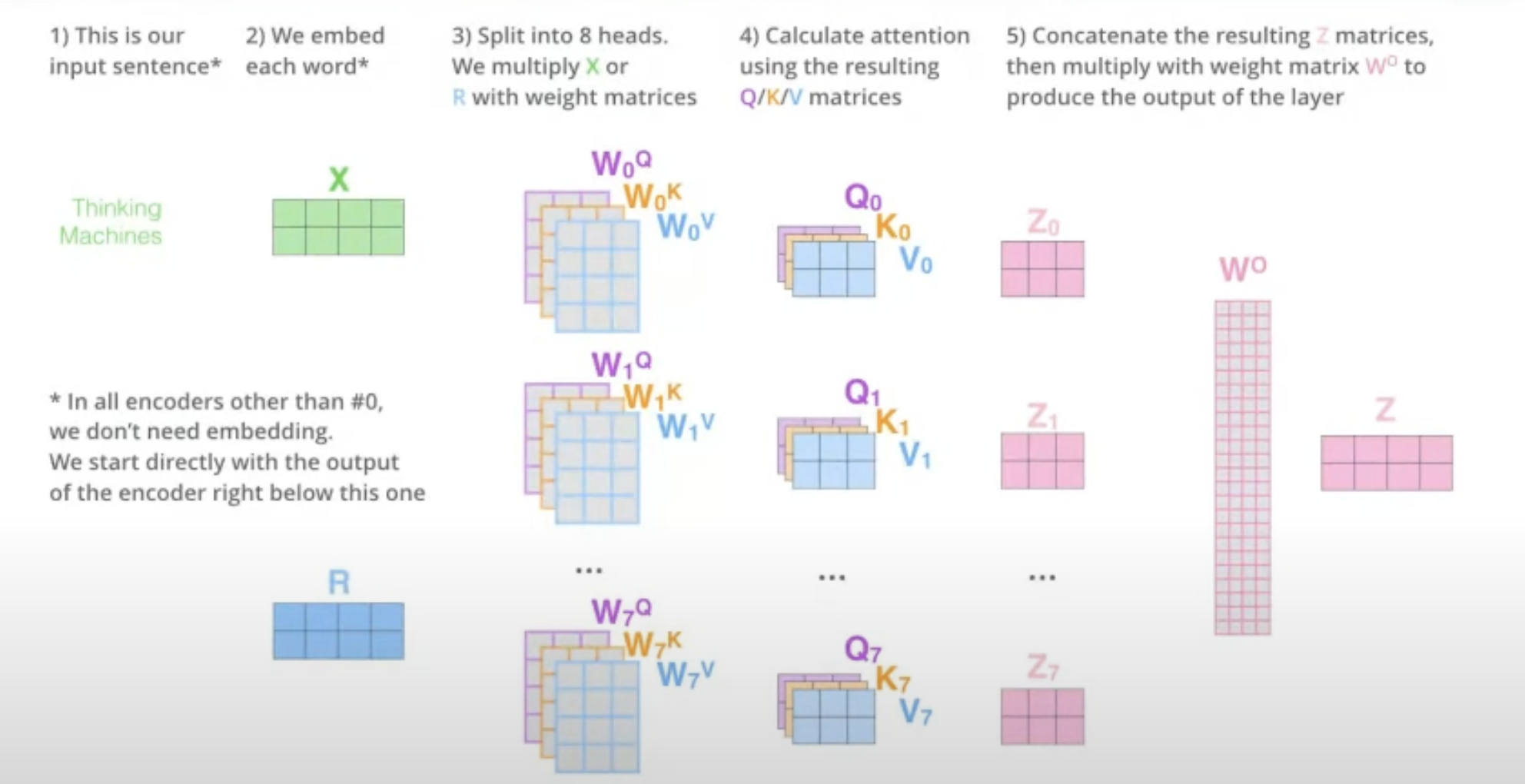
Step4. Feed-Forward Layer
문장 간의 관계보다는 자기 자신의 표현을 더 정확하게 하도록 하기위해 만들어진 Layer part로 식은 다음과 같다.
$FFN(x) = max(0, xW_1+b_1)W_2 + b_2$
여기서 나온 output은 다시 Input으로 들어가 2,3 과정을 거쳐야 하기에 반드시 1에서 Input Embedding을 했던 결과의 크기와 같아야 한다.
Decoder
Encoder에서는 multi-head attention을 사용해서 head수 만큼의 transformed된 Z vector를 output으로 내놓는다. 이 output을 통해서 Decoder에서는 auto-regressive하게 output sentence를 생성한다.
Step1. Decoder Input
우선 Decoder의 시작은 Encoder와 마찬가지로 특정 길이의 vector를 지정해두고 Embedding과 Positional Encoding을 거친다. Decoder Input은 특정 길이의 vector를 임의로 지정한다. 모델을 거치면서 [Start of Sentence]부터 Encoder의 input sentence에 대해 번역을 하거나 답변을 하는 Sentence를 [End of Sentence]가 예측되기 전까지 하나의 token씩 만든다.
Step 2. Masked Multi-head Self-attention
Decoder의 구조를 보면 Encoder와 다르게 Masked Multi-head attention이 있고 Encoder와 같은 Multi-head attention이 다음에 존재한다. attention 구조가 2개인 이유와 Masked인 이유는 다음과 같다.
- "”트랜스포머 모델은 인공지능의 혁신이다”.
- [SOS] Trasformer model is the ___ ___ ___ $\dots$ ___. (vector크기를 30이라고 가정)
1번 한글 문장을 2번처럼 영어로 번역하는 경우를 가정하자. 현재 Transformer is the까지 번역이 되었고 그 다음 token을 예측해야 하는 경우인데 이 때 Model은 1번문장도 당연히 참고해서 그 다음 Word를 예측해야 하기도 하지만, 번역이 되고 있는 2번 문장도 앞에 어떤 단어들이 예측되어 나왔는지 고려해야 한다. 이렇듯 Decoder는 2번문장 자기 자신도 고려하는 경우 Masked Multi-head attention을 사용한다. 근데 왜 Masked일까?
Transformer에서 Sentence를 생성할 때, 모든 문장내의 token을 한꺼번에 생성하는 것이 아니라 번역해야 할 혹은 답변해야 할 문장을 고려하고, 번역하거나 답변을 하고 있는 문장의 token들까지 고려하면서 token을 End of Sentence가 나오기 이전까지 하나하나씩 생성한다. 앞에서도 언급했듯이, Transformer는 Output된 결과가 계속 Input으로 다시 들어가면서 반복되는 구조이기에 이번에는 4번째 token을 생성해야 하니까 input vector의 크기를 4로 하고 다음번엔 5로 늘리는 방식을 택할 수가 없다. 즉, 생성해야 할 token의 길이를 제한을 해두고 처음부터 크기가 일정해야 한다. Attention 구조에서는 모든 token을 고려하기에 만약 Decoder가 위의 2번 예시에서 처럼 [SOS]를 포함해 5번째 token까지 생성하고 6번째 token을 생성해야 하는 경우 그 뒤의 token들은 masked처리를 해서 Attention에 반영되지 않도록 하는 것이다. 크기를 초기에 지정을 해놨기에 아직 생성하지 않은 ___ 들도 다 임의의 벡터이다. masked처리를 하지 않는다면 다음번에 생성될 token에 지장을 줄 수 있다.(Attention시, 반영되기 때문이다.)
Step3. Encoder-Decoder Attention
Multi-head Attention을 보면 입력 2가지는 Encoder로부터 오고, 1가지는 Decoder로 부터 온다.
- Query: the query from decoder
- Key, Value: the key and value from encoder
번역해야 할 문장은 Encoder를 통해 같은 크기의 Z 벡터로 표현이 된다. 이때 이 Z벡터를 가지고 Key와 Value를 삼고, Decoder에서 Masked-Multi Head attention을 거친 vector들을 Query로 삼아 Encoder에서와 똑같은 방법으로 attention기법을 취한다.
Step4. Feed-Forward
Encoder와 똑같다.
Step5. Linear + Softmax
Model을 거치고 나서 Input token 개수만큼 Output token이 나오면, 그 중에서 예측해야 할 token에 대해 Linear Layer를 쌓아서 Classifier를 둔다. 그래서 예측해야 할 token이 뭐가 되야 하는 지 softmax를 통해 확률을 계산하면서 가장 적합한 token을 선택하도록 하고 softmax값을 이용해 cross-entropy loss로 backpropagation을 진행한다.
Reference
https://www.youtube.com/watch?v=DVCbOfd09w8 - [딥러닝] Lecture 9. Attention Mechanism & Transformers I
https://www.youtube.com/watch?v=H6hFYlmmWGs&t=1186s - [딥러닝] Lecture 10. Transformers II
https://www.blossominkyung.com/deeplearning/transfomer-positional-encoding (정말 잘 정리해주신 블로그라고 생각합니다 최고에요..!!)