[Paper Review] UNet(Convolutional Networks for Biomedical Image Segmentation)
UNet(Convolutional Networks for Biomedical Image Segmentation)
최근 생성ai분야가 급부상하며 다양한 모델들이 사용되고 있다. 하나의 Domain뿐만 아니라 text, audio, image 등 여러 domain을 아우르며 생성을 하는 multi-modal AI가 대세이다. 수많은 모델 중 많은 모델들이 Diffusion에 기반한 Model을 base로 변형되었는데 이 Model에 U-Net구조가 사용되기에 공부해보기 위해 U-Net에 대해 알아볼 것이다.
Semantic Segmentation
이미지 내에서 사물을 인식하는 방법에는 여러가지가 있는데 그 중, Segmentation은 각 픽셀마다 클래스를 할당하는 작업을 의미한다. Semantic Segmentation은 각 물체(Object)들을 의미 있는(Semantic) 단위로 분할(Segmentation)하는 작업을 의미한다. 일반적인 Classification에서는 단일 이미지를 하나의 class로 구분했다면 Segmentation에서는 각 픽셀마다 하나의 class로 분류한다고 볼 수 있다.
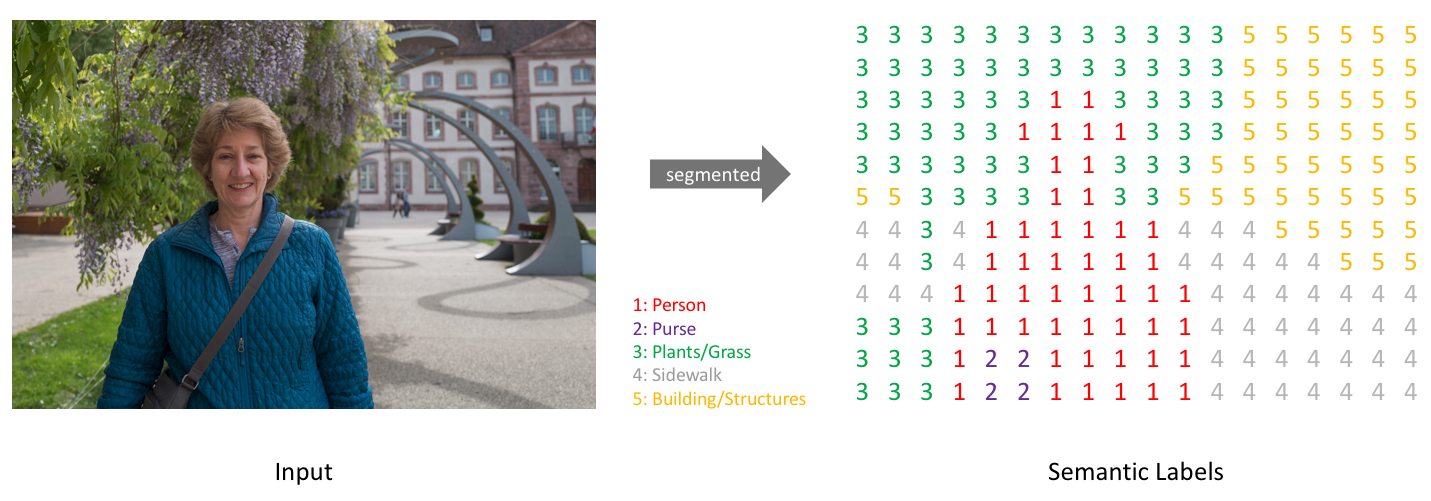

위의 그림과 같이 Semantic Segmentation을 이용하면 구분하고자 하는 Class의 개수만큼 One-hot Encoding이 되어 각 픽셀들이 예측되는 Class의 값들을 픽셀값으로 갖게 된다.
Semantic Segmentation은 CNN 분류 모델의 형식과 크게 다르지 않아 네트워크의 구조가 그리 어렵지 않기에 학습에 용이하며 대체적으로 Object Detection 모델들의 네트워크 구조가 훨씬 복잡하다.
U-Net
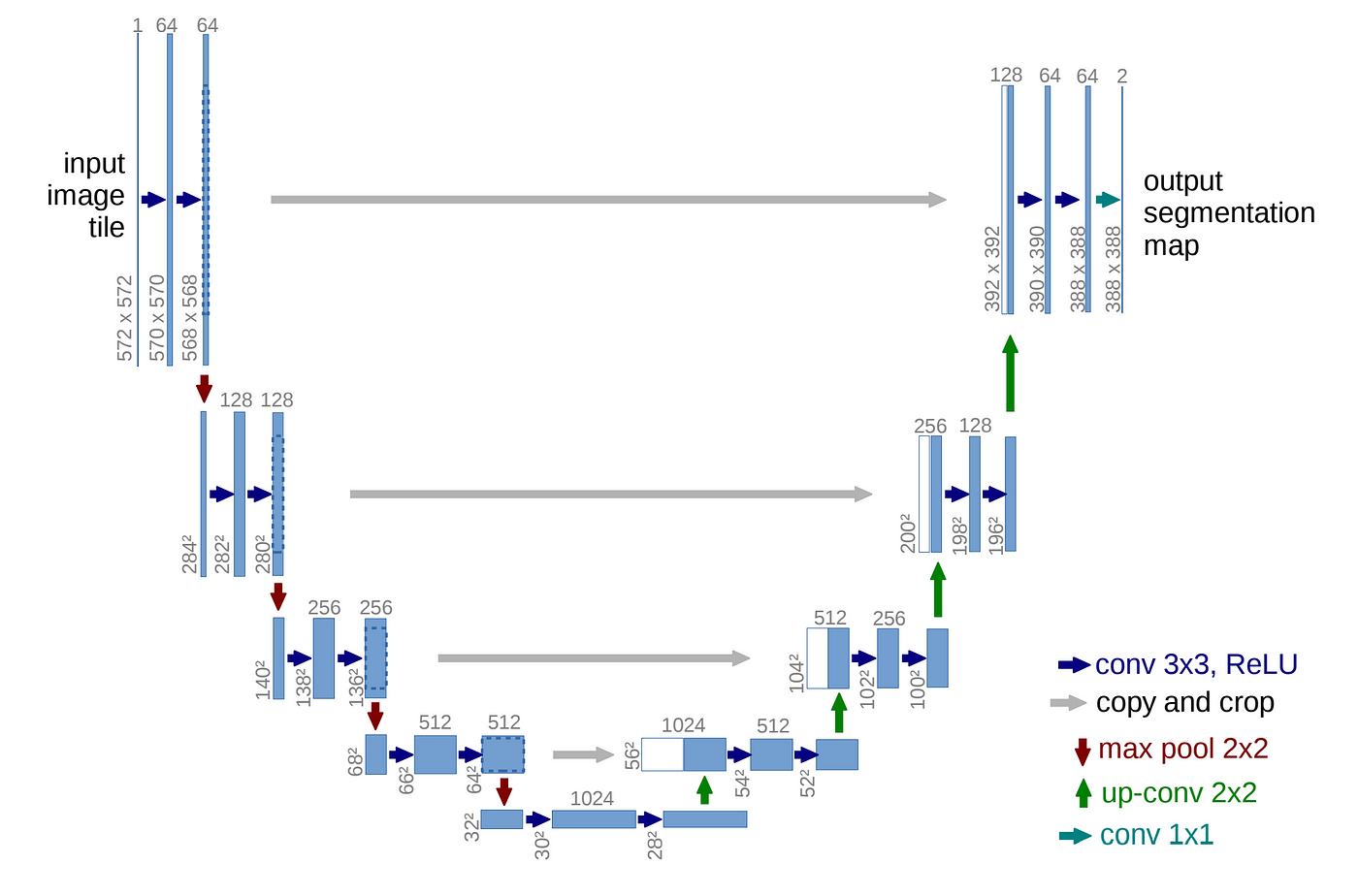
일반적인 Classification에서는 DownSampling을 통해 특징을 추출하고 Class를 분류하지만 이는 원본이미지에 비해 해상도가 낮다. U-Net은 의료분야에 사용하기 위해 제안된 Network로 특징 추출 뿐만 아니라 원본 이미지와 비슷한 해상도의 이미지를 얻는 것까지 목표로 하기에 DownSampling과 UpSampling이 모두 포함되어 있어 U자 구조의 형태를 띄어 U-Net이라고 불린다.
보통 Encoder, Decoder 구조의 모델은 Encoding 과정에서 차원축소를 거치면서 자세한 정보를 잃게 되고, Decoding 과정에서는 차원의 정보만을 이용하기 때문에 위치 정보 손실을 회복하지 못하게 된다. 이러한 단점을 해결하고자 U-Net에서는 인코딩 단계의 각 레이어에서 얻은 특징을 디코딩 단계의 각 레이어에 합치는(concatenation) 방법을 사용한다. 인코더 레이어와 디코더 레이어의 직접 연결을 스킵 연결(skip connection)이라고 한다.
위 그림에서 concatenation 방법을 보았을 때, 너비와 높이가 다른 것을 알 수 있는데 실제 Encoding과정에서의 feature map의 크기가 더 크기에 Decoding과정에 concatenate하기 위해 해상도(너비와 높이)를 크기에 맞게 줄인다고 한다. 아래 Encoder와 Decoder에 관한 설명에서는 설명상 편의를 위해 Encoder feature map과 Decoder feature map의 해상도가 같다고 설정하고 설명한다.
Encoder or 수축 경로(Contracting Path) : 이미지에 존재하는 넓은 문맥 처리
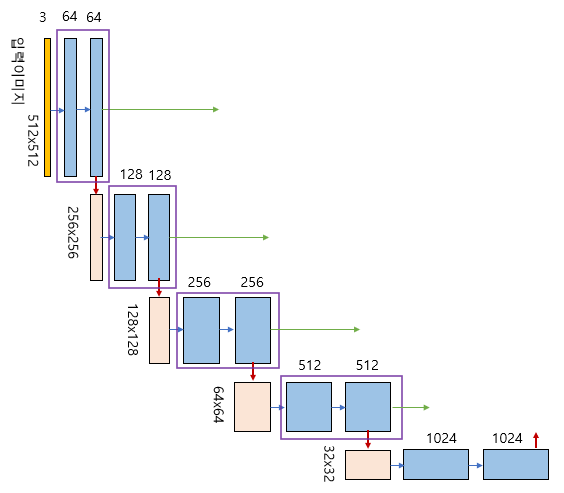
- 2x2 Max Pooling 사용 -> 해상도(너비와 높이) 감소
- Conv 연산으로 채널 크기는 2배 증가
- 일반적 CNN 모델처럼 ( Conv연산 -> ReLU -> Max Pooling ) 반복
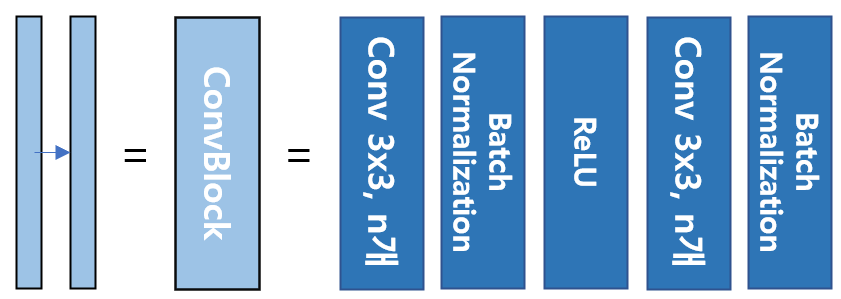
파란 부분은 하나의 ConvBlock으로 CNN 모델 구조에서 자주 사용하는 Conv + Batch Norm + ReLU 형태를 반복해서 사용한 부분으로 U-Net에서의 ConvBlock이라고 지칭한다. 같은 step에서는 3x3 Convolution을 사용하기에 크기는 변하지 않고 단지 channel수만 변하는 것을 볼 수 있다. 다음 step으로 넘어갈 경우, Max Pooling을 사용하기에 해상도(너비, 높이)와 관련된 부분이 절반씩 감소하는 것을 볼 수 있다.
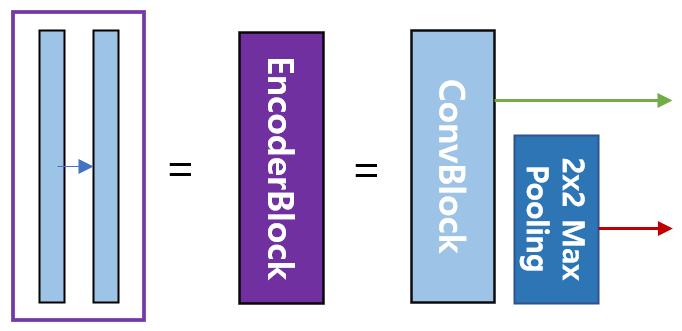
매 step마다 보라색 박스를 볼 수 있는데, 이를 EncoderBlock이라고 지칭한다. EncoderBlock을 보면 두 가지의 output을 확인할 수 있는데 한가지는 Decoding에 사용되기 위한 output이고 나머지는 Max Pooling을 거쳐 다음 Encoding step에 이용될 output이다.
Decoder or 확장 경로(Expanding Path): 정밀한 지역화(Precise Localization)
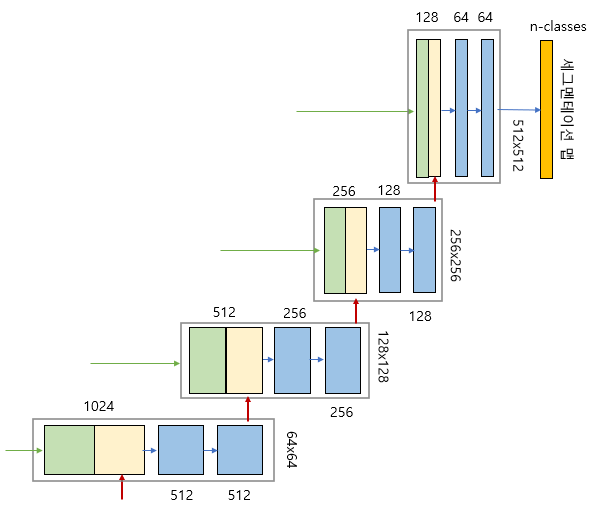
- 2x2 Convolution(Up-Convolution) 사용 -> 해상도(너비와 높이) 2배 증가
- Conv 연산으로 채널 크기는 2배 감소
- Encoding단계 레이어에서 얻은 특징을 Decoding단계 레이어에 Concatenate
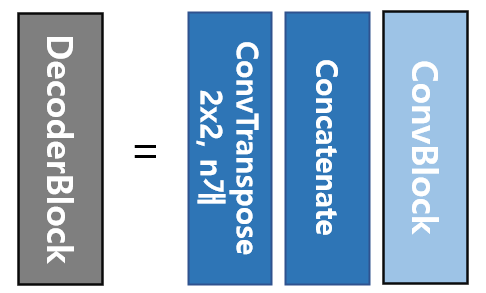
ConvTranspose를 통해 channel수는 줄이고 해상도는 증가시킨다. 이후 Encoder에서 사용한 feature map을 가져와 ConvTranspose의 결괏값과 concatenate한다. 그리고 Encoder와 마찬가지로 ConvBlock을 사용하여 concatenate함으로써 증가한 channel수를 다시 줄인다. 위의 과정을 반복하며 channel수는 계속해서 감소하고 해상도는 원본이미지와 비슷하도록 증가한다.
두 개의 맵을 서로 합쳐서(concatenation) 저차원 이미지 정보뿐만 아니라 고차원 정보도 이용할 수 있도록 설계한것이 U-Net의 특징이라고 볼 수 있다.
U-Net의 학습 방법
U-Net은 segmentation을 위한 네트워크이므로, 픽셀 단위로 softmax함수를 사용한다.
Loss함수로는 Classification 문제에서 흔히 사용하는 Cross-Entropy Loss를 사용한다.
$p_k(x) = \cfrac{exp(a_k(x))}{\sum_{k’=1}^{K}exp(a_{k’}(x))}$
$E = \sum_{x\in\Omega}w(x)log(p_{l(x)}(x))$ <l(x): 이미지 x의 true label, w(x): 추가적인 가중치 함수>
의료영상에서는 세포간에도 명확한 구분이 필요하기에, 작은 분리 경계(small seperation border)를 학습한다. w(x)는 인접한 셀 사이에 있는 배경 레이블에 대해 높은 가중치를 부여한다.
$w(x) = w_c(x) + w_0 \times exp(-\cfrac{(d_1(x) + d_2(x))^2}{2\sigma^2})$
$w_c(x)$: The weight map to balance the class frequencies
$d_1$ : The distance to the border of the nearest cell
$d_2$ : The distance to the border of the second nearest cell